
在這 CI/CD 工具多如繁星的現在,常常會造成不知道要選擇哪一套工具,所以了解工具的特點及優勢就顯的重要,而今年正式 GA 的 CDK Pipelines,到底有什麼特點及優勢呢?使用場景是什麼?真實環境使用上如何使用以及要注意什麼?這些都是我剛接觸 CDK Pipelines 會問自己的問題,先來講一下特點及優勢部分
特點及優勢
CDK Pipelines 是屬於 high level 的 CDK Construct,也就是比 L1 和 L2 Construct 還要高階,而 CDK Pipelines 是利用 AWS CodePipeline 來貫穿整個 CI/CD 流程,以下是個人認為的幾點特點和優勢
-
因為是 CDK construct,直接安裝後即可引用,不需要再設定如 GitHub Actions、Travis CI 等 yaml 設定檔,也就是 CI/CD 不需額外的設定,直接跟 CDK 代碼整合在一起,這點非常的方便
-
可以跨 AWS account 和 region 部署,這也是個人覺得最重要的功能,可以統一在一個 organization member account 管理其他 member account 的 Infra
-
只需要
cdk deploy一次後即搞定,之後只要 git commit and push 後,就會觸發 CodePipeline 自行運作 -
self-mutating 功能可以不斷擴展 AWS CodePipeline 的 stage 和 action,有高度的靈活性可以自行調配要達到的各種情境
缺點
-
因為太新了,所以範例太少,應用情境目前不多,所以要導入公司內部使用需要了解機制後再自行設計出符合公司內部需求的 pipelines
-
預設都是使用 cdk 最新版本,這部分似乎沒有選項可以指定版本,目前自己是用 workaround 的方式解決指定版本的問題 (個人覺得 Infra 穩定最重要,所以不一定要一直追 cdk 新版本,除非有想使用的新特性,例如 CDK v1.121.0 加入
cli --no-rollback實用參數,又或是版本太舊導致一些安全性問題,才需要更新),稍後案例也會介紹
補充更新,謝謝Scott Hsieh 的告知,有
cliVersionprop 可以用,程式碼已修改,請參考這裡
使用案例類型
使用案例類型,個人覺得以「目的」來區分最主要可以分 Application 和 Infra 這二種 (當然可能還有 Data 領域),Application 以應用程式包含商業邏輯部署為主角,如 CDK Pipelines Blog 就是以 ApiGateway + Lambda 來示範
而 Infra 主要以 AWS 基礎建設和服務為主,如 Network、RDS、ECS 等…,以 Infra team 的角度來考量,稍後實際案例會以這部分為主
當然這兩者多多少少都可能會相混到,而設計 CDK Pipelines 時所考量的點可能會有所差異,例如 Application 考量的可能是修改商業邏輯程式碼後,如何在管道中設計可以驗證 API 是否正常可以運作的測試,而 Infra 的考量可能以穩定為主,Synth 出來的 cfn 需要先行驗證等等…
概念介紹
這邊大略介紹一下運作的概念,實際細節可以參考官方文件
- 初始化 CDK 環境
這一步可說是相當重要,CDK Pipelines 強大的功能之一就是可以 cross account and region,跨 account 和 region 的相關權限設定,也在於這個步驟,首先在 CDK 專案中的 cdk.json 中加入
context: {
"@aws-cdk/core:newStyleStackSynthesis": true,
}
若是使用 projen,有 property context 可以直接設定,再來執行 cli 指令
env CDK_NEW_BOOTSTRAP=1 npx cdk bootstrap \
--profile 9incloud_dev \
--cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess \
aws://340227574277/ap-northeast-1
--profile 和 aws://{account}/{region} 這部分就替換成自己實際的設定即可,這邊額外要說明的,這種初始化 cdk 的方法是屬於 CDK v2 的作法,未來 v2 這是 default 作法,但目前大部分的人還是使用 v1,所以要額外指定 CDK_NEW_BOOTSTRAP=1,詳細說明可以參考這裡
記得這個指令需要在所有的 account 都執行過,包含使用 CDK Pipelines 本身這個 account
再來就是信任哪個 account 可以執行這個 account 的相關動作
env CDK_NEW_BOOTSTRAP=1 npx cdk bootstrap \
--profile 9incloud_dev \
--cloudformation-execution-policies arn:aws:iam::aws:policy/AdministratorAccess \
--trust 794029059620 \
aws://340227574277/ap-northeast-1
這邊跟剛才的指令相比只多了 --trust 794029059620,794029059620 這個帳號就是實際跑 CDK Pipelines 的 AWS account,換句話說,就是 CDK 相關的部署動作,都集中在這個帳號管理
而一般公司區分 SDLC 和 production 環境,這邊有多少 account 就執行幾次,但要額外注意的是,因為是 AdministratorAccess 權限,所以文件有說明不要執行在 production 環境,但我自己的作法是,在 Organization 中獨立一個 account 專門給 CDK Pipelines 使用,這個 account 只有管理者或有相關的開發人員才能使用,就比較不會有安全的疑慮
- 生成 AWS CodePipeline
寫好相關的 stage、stack,搭配 CDK Pipelines construct,執行 cdk deploy 後,就會產生如下 CodePipelines
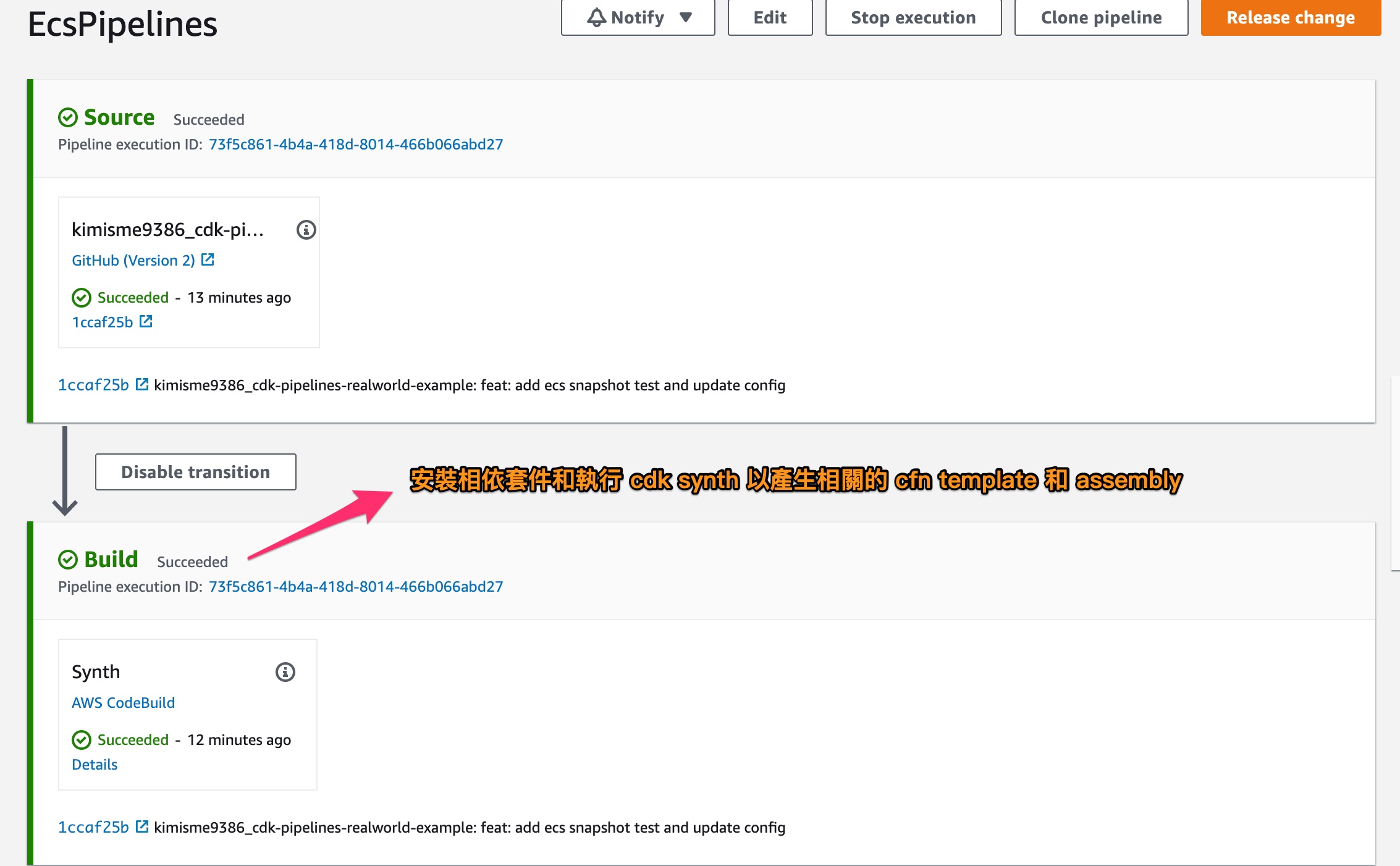
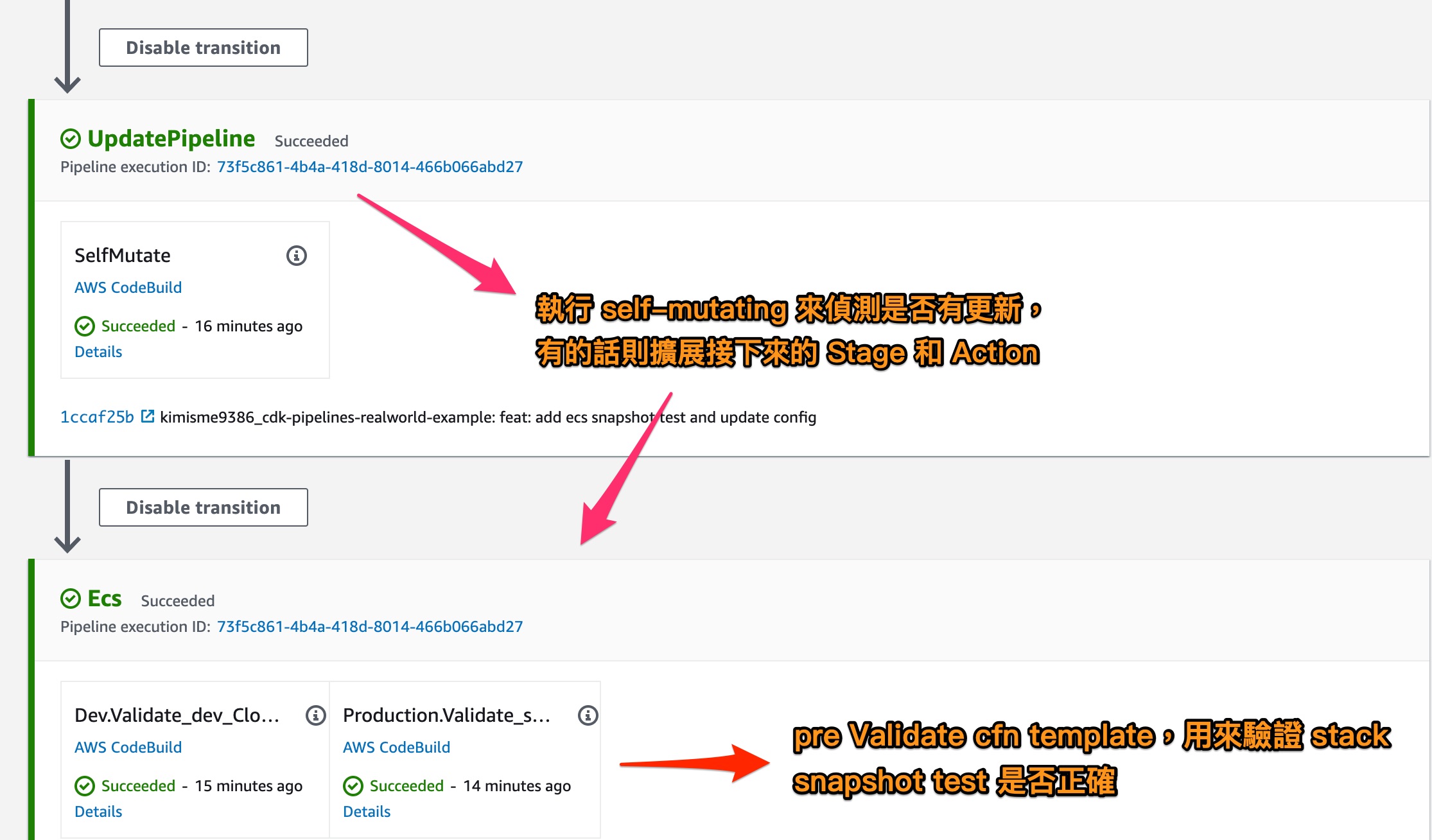
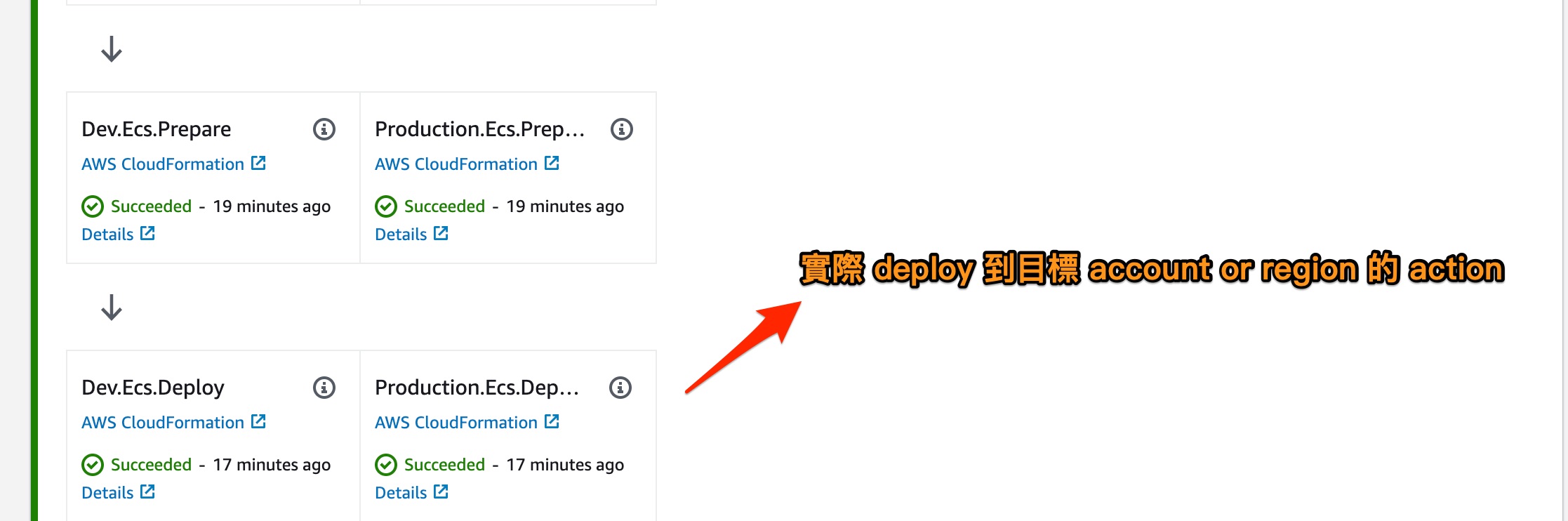
在截圖中已經的略的說明,而在 SelfMutate 以上都是 CDK Pipelines 基底會產生的 stage 流程,而 SelfMutate 就全部是可以客製化的部分
實際案例與小技巧
從概念介紹已經知道,雖然 CDK Pipelines 可以使用 self-mutating 來不斷擴展 AWS CodePipeline Stage 和 Action,但從實務上設計來看,不可能把所有的 Infra 和相關服務都放在同一個 CodePipeline
目前想到有 2 種方式來設計區分,第一種把「相關」的服務放在同一個 CodePipeline,例如 Network 相關放在一起、ECS 相關放在一起等…,第二種是以「單一服務」來區分,例如會員系統服務,這個服務的 Network、ECS、RDS 等都放在同一個 CodePipeline,這 2 種方式可能也要看團隊狀況來做選擇,目前自己是用第一種方式來設計
- 目錄與檔案結構
project
│ README.md
│ config.yml
│
└───src
│ │ main.ts
│ │
│ └───network
│ │ cdk-pipelines.ts
│ │ network-stage.ts
│ │ network-stack.ts
│ │ ...
│ └─── configs
│ │ dev.yml
│ │ prod.yml
│ └───ecs
│ │ cdk-pipelines.ts
│ │ ecs-stage.ts
│ │ ecs-stack.ts
│ │ ...
│ └─── configs
│ │ dev.yml
│ │ prod.yml
│
└───test
│ network-dev.test
│ network-prod.test
│ ecs-dev.test
│ ecs-prod.test
以上細節可以在 GitHub 上看到,這邊大略說明一下
-
root config.yml: 這邊可以放置想要 fixed 的 cdk version,各環境的 AWS account 的資訊等
-
src/network、src/ecs: 使用資料夾把服務切分出來
-
src/network/configs、src/ecs/configs: 因為各服務在不同的環境可能會有不同的設定,故這樣設計
-
test: 這邊也是之前有提到的,每個服務中的 stack synth 出來的 cfn 需要先行驗證,才能確保 cfn 異動的狀況,確保每次的修改,infra 工程師都已確認過,避免影響到線上服務,這邊的 test 並不包含 cdk pipelines 本身的 CodePipeline,而是針對目標 account or region 的 stack 做測試
- cdk diff 與測試 cfn
站在 Infra 的角度來看,服務穩定最重要,所以一般修改完程式碼後,會先 cdk diff 來看看變化,也就是 synth 出來的 cfn template 有什麼改變,但如果直接下 cdk diff,是 diff CDK Pipelines 本身的 CodePipeline,並不是 diff 要 deploy 到目標 account 的 stack
所以這邊提供一個小技巧,以我自己的 GitHub 為例,用以下的指令
Diff Network Dev 環境
cdk synth -q && cdk diff -a cdk.out/assembly-TestNetwork-Dev
Diff Network Production 環境
cdk synth -q && cdk diff -a cdk.out/assembly-TestNetwork-Production
Diff ECS Dev 環境
cdk synth -q && cdk diff -a cdk.out/assembly-TestEcs-Dev
其他依此類推,那如果剛寫完一個 stack,我想測試看看,先不透過 CDK Pipelines,而是用手動 deploy 在目標 account,並且加上 -–no-rollback 來停用 rollback,以便有任何失敗時,可以在修改完程式碼後,繼續在失敗的點繼續 deploy,那可以用以下指令
cdk synth -q && cdk deploy -a cdk.out/assembly-TestEcs-Dev -–no-rollback
如此一來,既可以使用 CDK Pipelines 強大的功能,又可以在開發、測試階段時,用以上指令來方便測試和部署,而且之後有做任何修改時,都可以先 diff 看看差異,再更新 snpashot test,否則也會被 pre Validate cfn template 這個 action 擋下來,這樣一來,對於線上服務就更有保障了
而 pre Validate cfn template 可以這麼撰寫
const ecsWave = pipeline.addWave('Ecs');
ecsWave.addStage(
new EcsStage(this, 'Dev', {
env: { account: props.devAccount, region: 'ap-northeast-1' },
stageEnv: 'dev',
}),
{
pre: [new pipelines.ShellStep('Validate dev CloudFormation Synth', {
commands: [
'yarn install --frozen-lockfile',
'./node_modules/.bin/jest --passWithNoTests test/ecs-dev.test.ts',
],
})],
},
);
ecsWave.addStage(
new EcsStage(this, 'Production', {
env: { account: props.prodAccount, region: 'ap-northeast-1' },
stageEnv: 'prod',
}),
{
pre: [new pipelines.ShellStep('Validate staging CloudFormation Synth', {
commands: [
'yarn install --frozen-lockfile',
'./node_modules/.bin/jest --passWithNoTests test/ecs-prod.test.ts',
],
})],
},
);完整的程式碼可以參考這裡,可以看到重點在 pre 區塊,加入了 jest 的測試,所以每個 stack 都獨立一個測試檔以方便在 pre 中引入當作測試,這也確保每一次更改,都是經過檢視過後去 update snapshot,才會 pass 這個測試
這也避免修改完程式碼後,一旦動作太快 commit 和 push 後,就馬上把線上服務更新的問題,可以避免掉一些潛在的風險
結論
CDK 相關的生態圈和工具已經愈來愈進步與成熟,相信也是未來的大趨勢,而 IaC 也已經愈來愈普遍,如果有好的 CI/CD 工具,更可以讓 IaC 的流程更加順暢,以 CDK 來說,自家工具整合起來一定更順手,再加上 CDK Pipelines 的設計上非常靈活,都可以自己再客製流程,相信是企業導入 CDK 可以優先考量的 CI/CD 工具,也希望大家可以愉快的使用 CDK Pipelines
